Register Allocation by Puzzle Solving
Experimental Results
In order to show that puzzles can be effective and useful to register allocation, we have implemented a register allocator based on puzzles. We have implemented our register allocator in the LLVM compiler framework, version 1.9. Our tests are executed on a 32-bit x86 Intel(R) Xeon(TM), with a 3.06GHz cpu clock, 3GB of free memory and 512KB L1 cache running Red Hat Linux 3.3.3-7. Currently our allocator passes all the tests that LLVM passes using its default allocator. In this page we show results of our experiments. We have been able to compile and run over 1.3 million lines of code, and the results are encouraging. The next sequence of tables use the following key:
- Program: the name of the program that is been compiled
- GCCAS: the compilation time of gccas.
- Bytecode: size of the LLVM bytecode, in bytes.
- LLC compile: the compilation time of llc.
- LLC-Beta compile: the compilation time of the beta-version of llc. In many of the experiments, the beta-version will be running our puzzle solver register allocator.
- JIT codegen: the compilation time of the code generator used by LLVM JIT compiler only. We disabled this option in all our experiments because we were running all our benchmarks off-line.
- GCC: the running time of the benchmark as compiled with gcc -O3.
- CBE: the running time of the application as produced by the C-backend used by LLVM. In this case, the LLVM bytecode is first compiled into C, which is then compiled into native code without further optimizations. It took me a little while until I realized that I could disable the CBE. This information is not important in our experiments.
- LLC: This tool compiles LLVM bytecodes into assembly code. This column reports the running time of the application, and is the main information we will be interested in order to check the running time of the compiled application.
- LLC-BETA: LLVM allows to define an alternative beta llc compiler, and we will use it to compare to different register allocators.
- JIT: the running time of the application as compiled by the JIT. We do not use this data.
- GCC/CBE: ratio between running time of application compiled with gcc and the cbe.
- GCC/LLC: ratio between running time of application compiled with gcc and the llc.
- GCC/LLC-BETA: ratio between running time of application compiled with gcc and the llc-beta.
- LLC/LLC-BETA: ratio between running time of application compiled with llc and the llc-beta. In the test where the beta compiler is enabled, this is the really important number.
The LLVM test suite provides a large number of benchmark applications. In addition to these benchmarks, we have also compiled SPEC CPU 2000. Unfortunately, one of the benchmarks: eon, cannot be run in our programming environment - even when compiled with gcc. The other floating point benchmarks, e.g wupwise, swim, mgrid, applu, etc, cannot be compiled because they are FORTRAN applications, and our compiler only handles C/C++ code. Nevertheless, we could compile all the integer benchmarks, and all the four floating-point applications implemented in C. This is the data that we have used in our paper. Due to space constraints, we could not include all the other benchmarks in the LLVM test suite in the paper, so we show it in this page. In general, the results for SPEC 2000 mirror the general behavior of the other benchmarks. The table below contains links to all the raw data that we have been gathering while implementing and debugging the puzzle solver. The rows are chronologically ordered, so they give a good idea of how our implementation has evolved.
We compare our puzzle solver with three other register allocators, all implemented in LLVM 1.9 and all compiling and running the same benchmark suite of 1.3 million lines of C code. The first is LLVM's default algorithm, which is an industrial-strength version of linear scan. The algorithm does aggressive coalescing before register allocation and handles holes in live ranges by filling them with other variables whenever possible. We use ELS (Extended Linear Scan) to denote this register allocator.
The second register allocator is the iterated register coalescing of George and Appel with the extensions by Smith, Ramsey, and Holloway presented in PLDI 2004 for handling register aliasing. We use EIRC (Extended Iterated Register Coalescing) to denote this register allocator. The third register allocator is based on partitioned Boolean quadratic programming (PBQP). The algorithm runs in worst-case exponential time and does optimal spilling with respect to a set of Boolean constraints generated from the program text. We use this algorithm to gauge the potential for how good a register allocator can be. Lang Hames and Bernhard Scholz produced the implementations of EIRC and PBQP that we are using.
| File | Date | Comments |
|---|---|---|

|
Jul 7, 2007 | The first tests with the puzzle solver! None many files could be compiled then... |
|
|
Jul 8, 2007 | |
|
|
Jul 9, 2007 | |
|
|
Jul 10, 2007 | A test with LLVM's default algorithm. Only to know how many programs are compiled with LLVM. |
|
|
Jul 14, 2007 | The puzzle solver again. |
|
|
Jul 19, 2007 | |
|
|
Jul 21, 2007 | |
|
|
Jul 27, 2007 | |
|
|
Jul 28, 2007 | |
|
|
Jul 31, 2007 | |
|
|
Aug 15, 2007 | |
|
|
Aug 20, 2007 | |
|
|
Aug 23, 2007 | |
|
|
Sep 5, 2007 | |
|
|
Sep 14, 2007 | An early experience with a different algorithm to split live ranges. The basic register allocator is still the puzzle solver. |
|
|
Sep 14, 2007 | Second run with the new algorithm to split critical edges. This algorithm was only used twice. |
|
|
Sep 18, 2007 | Graph coloring versus PBQP. LLC runs graph coloring. The beta compiler runs PBQP. |
|
|
Sep 18, 2007 | LLC running PBQP. |
|
|
Sep 18, 2007 | The puzzle solver. |
|
|
Sep 20, 2007 | |
|
|
Sep 23, 2007 | |
|
|
Sep 24, 2007 | LLVM's default versus the puzzle solver, with no instruction folding allowed to either allocator. LLC-BETA is the puzzle solver. |
|
|
Sep 24, 2007 | LLC running PBQP. |
|
|
Sep 24, 2007 | Puzzles versus LLVM's default. LLC is running puzzles. |
|
|
Sep 28, 2007 | LLVM's default versus puzzle in the full LLVM test suite. LLC is running LLVM's default. |
|
|
Oct 17, 2007 | |
|
|
Oct 18, 2007 | Graph coloring (LLC) versus PBQP (LLC-BETA). |
|
|
Oct 29, 2007 | LLVMS's default (LLC) versus puzzles. |
|
|
Oct 30, 2007 | Graph coloring (LLC) versus PBQP. |
|
|
Oct 31, 2007 | LLVMS's default (LLC) versus puzzles. |
|
|
Nov 3, 2007 | LLVMS's default (LLC) versus puzzles. |
|
|
Nov 4, 2007 | Graph coloring (LLC) versus PBQP. |
|
|
Nov 4, 2007 | |
|
|
Nov 4, 2007 | Graph coloring (LLC) versus PBQP. |
|
|
Nov 5, 2007 | LLVMS's default (LLC) versus puzzles. |
|
|
Nov 6, 2007 | LLVMS's default (LLC) versus puzzles. |
|
|
Nov 8, 2007 | LLVMS's default (LLC) versus puzzles. |
|
|
Nov 8, 2007 | Graph coloring (LLC) versus puzzles. |
|
|
Nov 9, 2007 | Graph coloring (LLC) versus PBQP. |
|
|
Nov 9, 2007 | PBQP |
|
|
Nov 10, 2007 | Graph coloring (LLC) versus PBQP. |
|
|
Nov 11, 2007 | Graph coloring (LLC) versus PBQP. |
|
|
Nov 12, 2007 | Graph coloring (LLC) versus LLVM's default. |
|
|
Nov 13, 2007 | Graph coloring (LLC) versus LLVM's default. |
|
|
Dec 1, 2007 | Puzzles versus LLVM's default in LLVM's benchmark suite. |
|
|
Dec 1, 2007 | Puzzles versus LLVM's default in LLVM's benchmark suite. |
|
|
Dec 1, 2007 | Puzzles versus LLVM's default in LLVM's benchmark suite. |
|
|
Dec 1, 2007 | Puzzles versus LLVM's default in LLVM's benchmark suite. |
|
|
Dec 1, 2007 | Puzzles versus LLVM's default in LLVM's benchmark suite. |
Spec CPU 2000
We have used SPEC CPU 2000 in most of our experiments. And some of the results we have found are summarized in the next charts. Notice that we do not present data for ten of the floating point programs. These benchmarks could not be compiled by LLVM in our machine. This is not a problem with the puzzle solver, because these floating point benchmarks could not be compiled even with the default allocator of LLVM. In fact, LLVM with its default allocator, or with the puzzle solver, pass the same amount of tests. I think the problem is support for sse floating point instructions in LLVM. Yet, the set of spec benchmarks that we use are the same that has been used in the paper "Demand-Driven Alias Analysis for C", by Zheng and Rugina.
Stack Size
This chart compares the maximum amount of space that each assembly program reserves on its call stack. The stack size gives an estimate of how many different variables are being spilled by each allocator. The puzzle solver and extended linear scan (LLVM's default) tend to spill more variables than the other two algorithms.
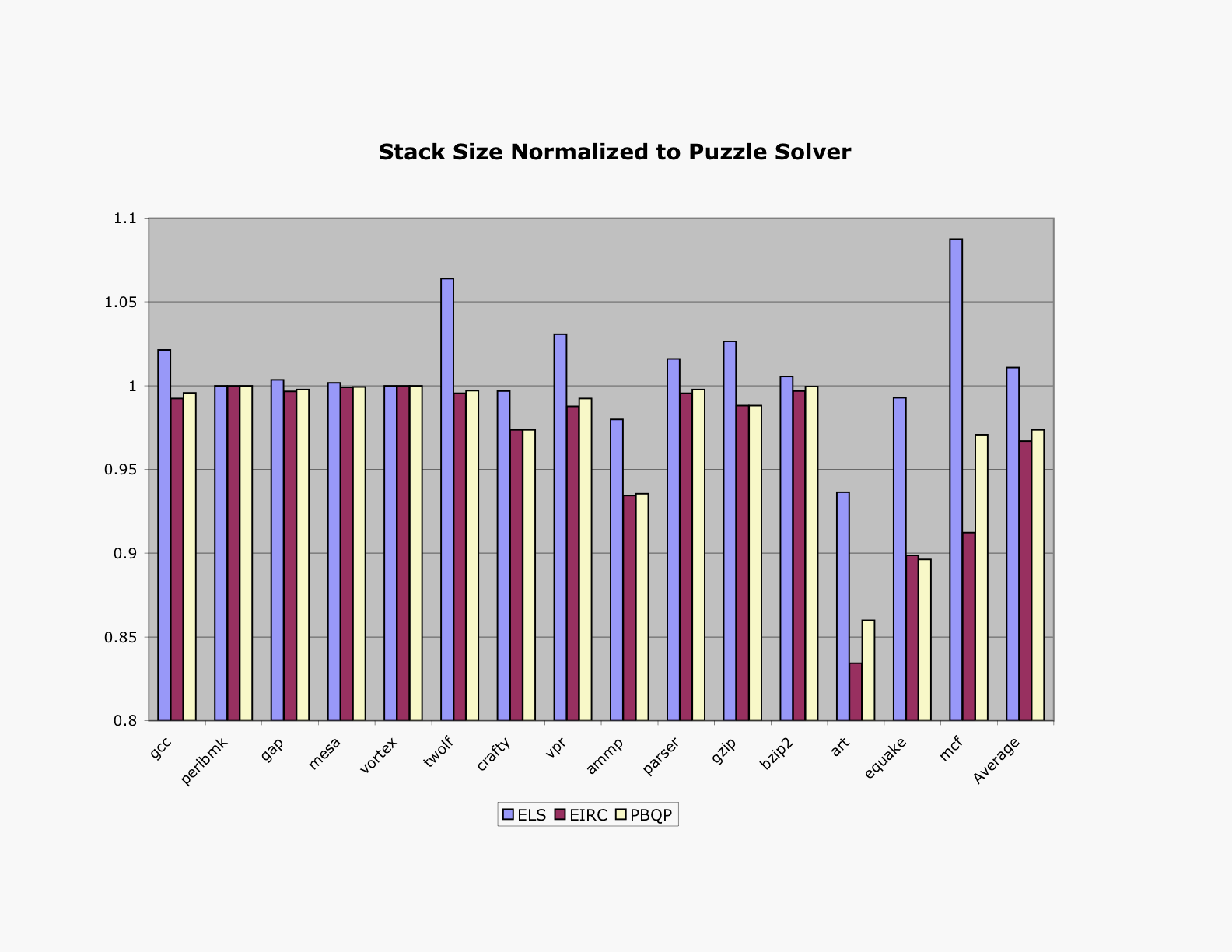
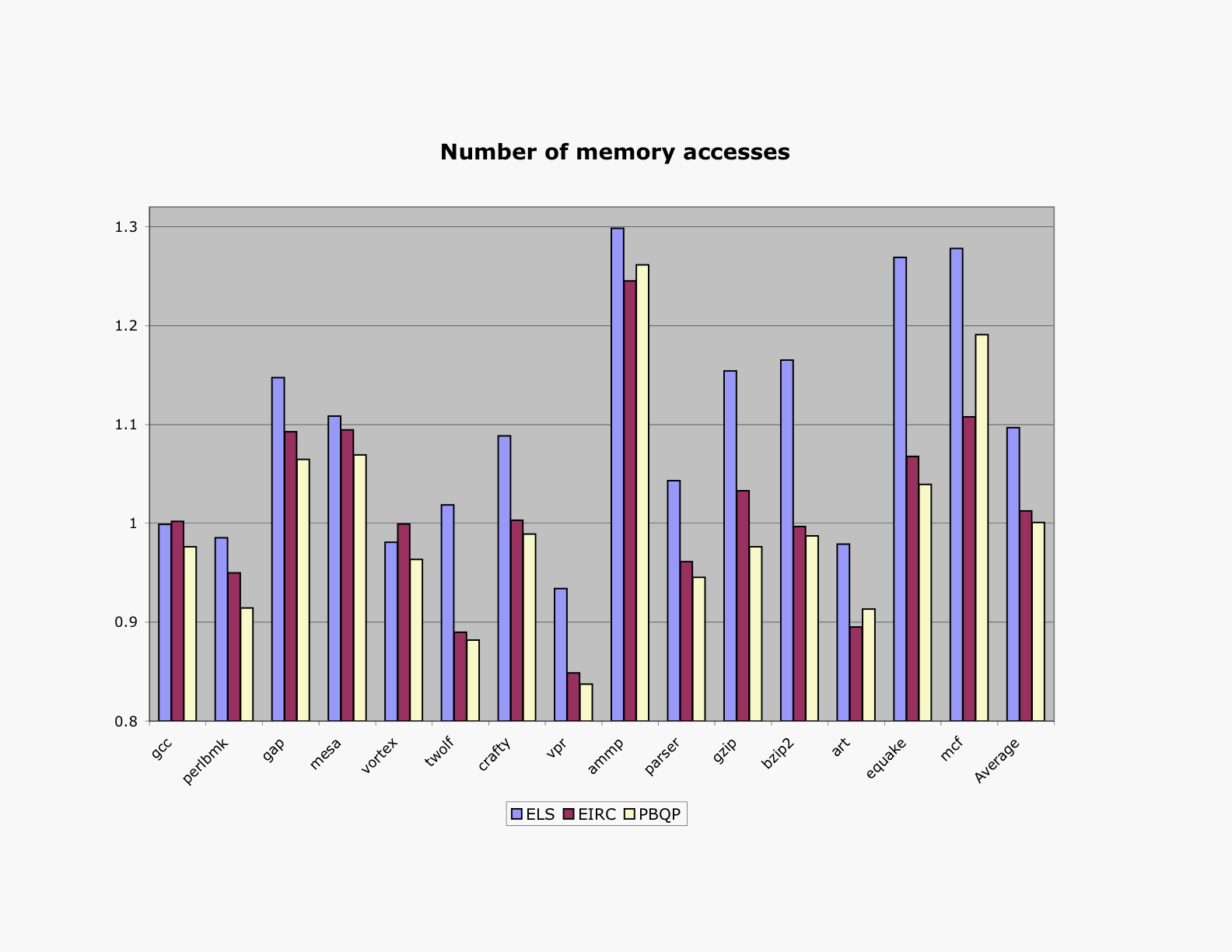
Memory Accesses
This chart shows the amount of spill code produced by each allocator when compiling SPEC2000. The puzzle solver inserts marginally fewer memory-access instructions than PBQP, 1.2 fewer memory-access instructions than EIRC, and 9.6% fewer memory-access instructions than extended linear scan (LLVM's default). Note that although the puzzle solver spills more variables than the other allocators, it removes only part of the live range of a spilled variable. The bars are normalized to the puzzle solver.
Compilation time
The chart below compares the register allocation time and the total compilation time of the puzzle solver and extended linear scan (LLVM's default). On average, extended linear scan (LLVM's default) is less than 1 faster than the puzzle solver. The total compilation time of LLVM with the default allocator is less than 3% faster than the total compilation time of LLVM with the puzzle solver. We note that LLVM is industrial-strength and highly tuned software, in contrast to our puzzle solver.

Size of Assembly Per Compilation Time
The next chart compares the ratio between the size of the assembly code produced by the compiler and the compilation time of the register assignment pass. We only compare two algorithm: the puzzle solver, and extended linear scan, the default algorithm of LLVM. The final column in the chart gives the standard deviation found for each algorithm. We see that the puzzle solver has a much more predictable behavior than LLVM's default, that is, the time spent by the puzzle solver in the register allocation process is much more proportional to the size of the assembly code produced than the time spent by ELS. The last column of the chart gives the standard deviation for each algorithm. The standard deviation for the puzzle solver is 66467.11244, whereas the standard deviation of LLVM's default is 386426.5572. In other words, the deviance of ELS is 5.83 times bigger than that of the puzzle solver.
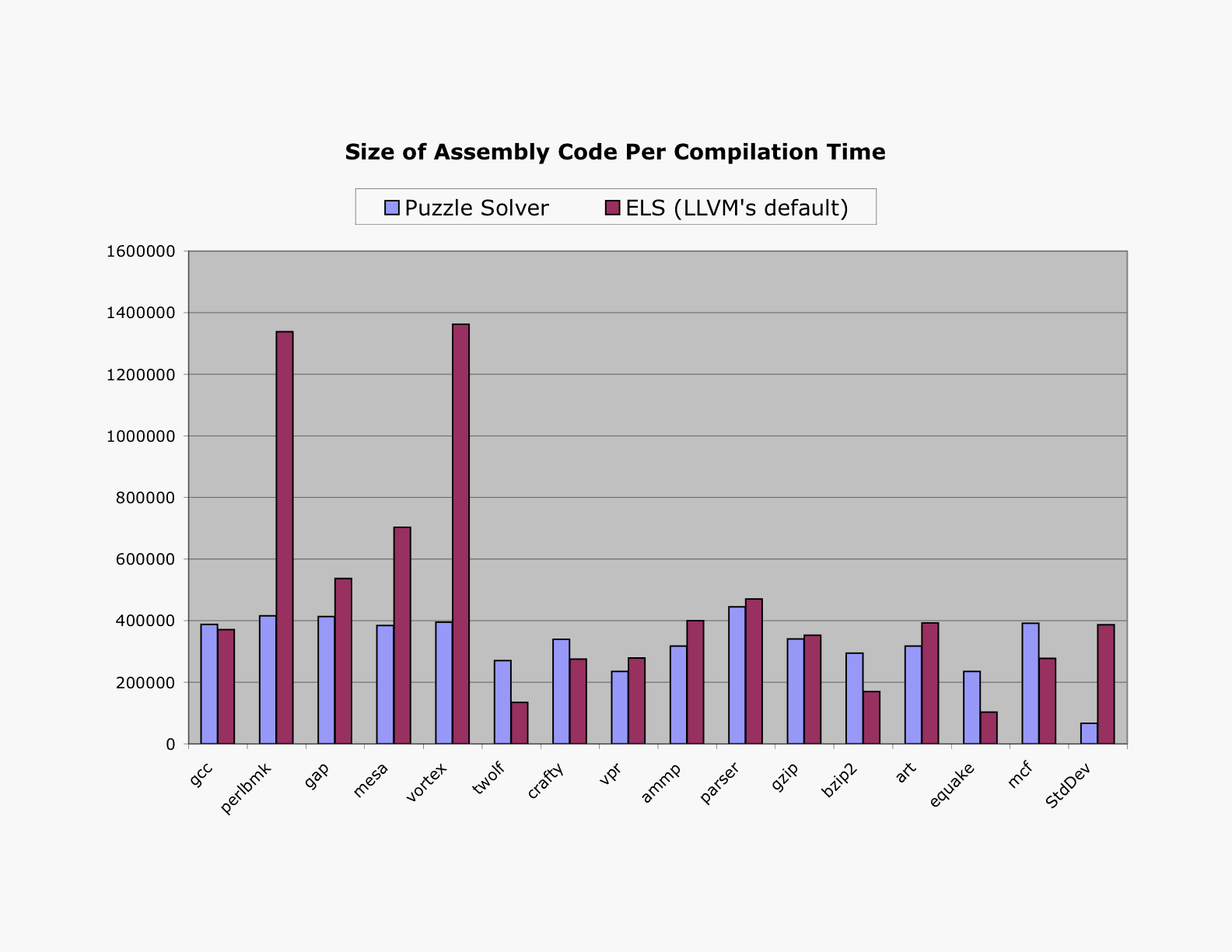
Running Time
This chart gives the run time of each benchmark compiled with different algorithms. The run time is normalized to gcc -O3, and it is the average of five runs of each benchmark. Considering all the benchmarks, the four allocators produce faster code than gcc; the fractions are: puzzle solver 0.944, extended linear scan (LLVM's default) 0.991, EIRC 0.954 and PBQP 0.929. If we remove the floating point benchmarks, i.e., mesa, amp, art, equake, then gcc -O3 is faster. The fractions are: puzzle Solver 1.015, extended linear scan (LLVM's default) 1.059, EIRC 1.025 and PBQP 1.008.

Number of move/swap instructions inserted per total of puzzles
The chart below reports on the number of move and swap instructions necessary to implement parallel copies, fixing the coloring between different puzzles. As the chart shows, a very small number of moves is necessary between consecutive puzzles. This is mostly due to our allocation order, that starts at the root of the dominator tree, and goes down toward the leaves. Move moves are necessary to implement phi and pi functions than internal parallel copies, although there exist many more of these parallel copies than phi and pi functions.
